In Distributed DBs, Consistency is evaluated based on CAP theorem. This post doesn't go into CP vs AP debate of CAP, but just address what consistency means in Distributed DBs. It starts with ideal scenario and then concludes with practically possible consistency level.
In perfect world, a distributed database system will be considered Consistent if an update is applied to all nodes at same logical time, i.e. it's instantaneous and global just like updating a DB with single node.

As shown above, client makes call to insert data and then DB initiates insertion to all data nodes (primary and replica) at same time. And because all nodes are similar so they take exactly same time to insert record. Is it possible ?
You might argue that, all nodes should be able to perform the operation in same time; so it's possible.
If you still feel this is possible - think hard. We are talking about distributed DB, which means they are at different places. All, sorts of things are possible while communicating - hardware might fail, network connectivity might fail or slow down.
How you synchronize, if update on one node fails ?
Perfect world is impossible for distributed DB !
In Practical world, a distributed database system is considered consistent if it applies update to all nodes in a synchronized way and then confirms to the client that update is successful. So, if there is one primary nodes and 2 replicas. Then DB should make sure that replicas get updated along with primary nodes. This can be done, but it comes at a cost.

Practical world is strongly consistent, but latency goes for a toss.
Practical world is not going to help us either!
We have only one option, store/update data on only one (primary/master) node and then update other nodes asynchronously.

Let's see how it's going to work when next request comes to read the data which is still undergoing replication to other nodes in asynchronous manner. In this case, system will behave depending on how the request gets handled. Below are possibilities:
In perfect world, a distributed database system will be considered Consistent if an update is applied to all nodes at same logical time, i.e. it's instantaneous and global just like updating a DB with single node.

You might argue that, all nodes should be able to perform the operation in same time; so it's possible.
If you still feel this is possible - think hard. We are talking about distributed DB, which means they are at different places. All, sorts of things are possible while communicating - hardware might fail, network connectivity might fail or slow down.
How you synchronize, if update on one node fails ?
Perfect world is impossible for distributed DB !
In Practical world, a distributed database system is considered consistent if it applies update to all nodes in a synchronized way and then confirms to the client that update is successful. So, if there is one primary nodes and 2 replicas. Then DB should make sure that replicas get updated along with primary nodes. This can be done, but it comes at a cost.
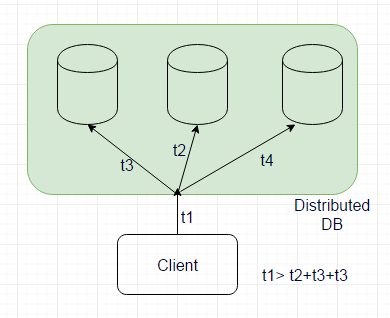
In practical world, DB will ensure that all nodes are updated before confirming to the client that operation is successful. In worst case, each node can take it's own sweet time to ensure that write/update is successful.
This can clearly mean that time, t1 >> t2 + t3 + t4
Host, might be unreachable for some time or it can go down. And unless, all nodes are updated; request will not be successful.
Your update is going to be slow and worst case really slow which will increase latency numbers and reduce throughput. Such system will not scale.
This can clearly mean that time, t1 >> t2 + t3 + t4
Host, might be unreachable for some time or it can go down. And unless, all nodes are updated; request will not be successful.
Your update is going to be slow and worst case really slow which will increase latency numbers and reduce throughput. Such system will not scale.
Practical world is strongly consistent, but latency goes for a toss.
Practical world is not going to help us either!
Consistency in Distributed DBs
Quite obviously above approaches (which will bring strong consistency to system) is not practical, and it wont be exaggeration to say Impossible!. So, what option we have ?We have only one option, store/update data on only one (primary/master) node and then update other nodes asynchronously.

Let's see how it's going to work when next request comes to read the data which is still undergoing replication to other nodes in asynchronous manner. In this case, system will behave depending on how the request gets handled. Below are possibilities:
- Any node can return value. Now, if the primary node returns the value then it will be most recent but if a node which is yet to get the update will return stale or old value. This is Week Consistency. This approach is used to achieve high availability.
- Only the primary node handles the request so you get the latest value. If DB can ensure that the data is returned from the primary node then client will get most recent value. This is Eventual Consistency.
Very good article... Keep it up...
ReplyDelete